Member-only story
Systematic Sampling
What is systematic sampling?
There are many ways to take a sample from a population. One popular way is to take a systematic sample.
This article looks at this sampling method, and the precision of resulting estimates.
Taking a sample
Surveys help researchers answer questions about a population. There are units — like people or businesses — that make up a population.
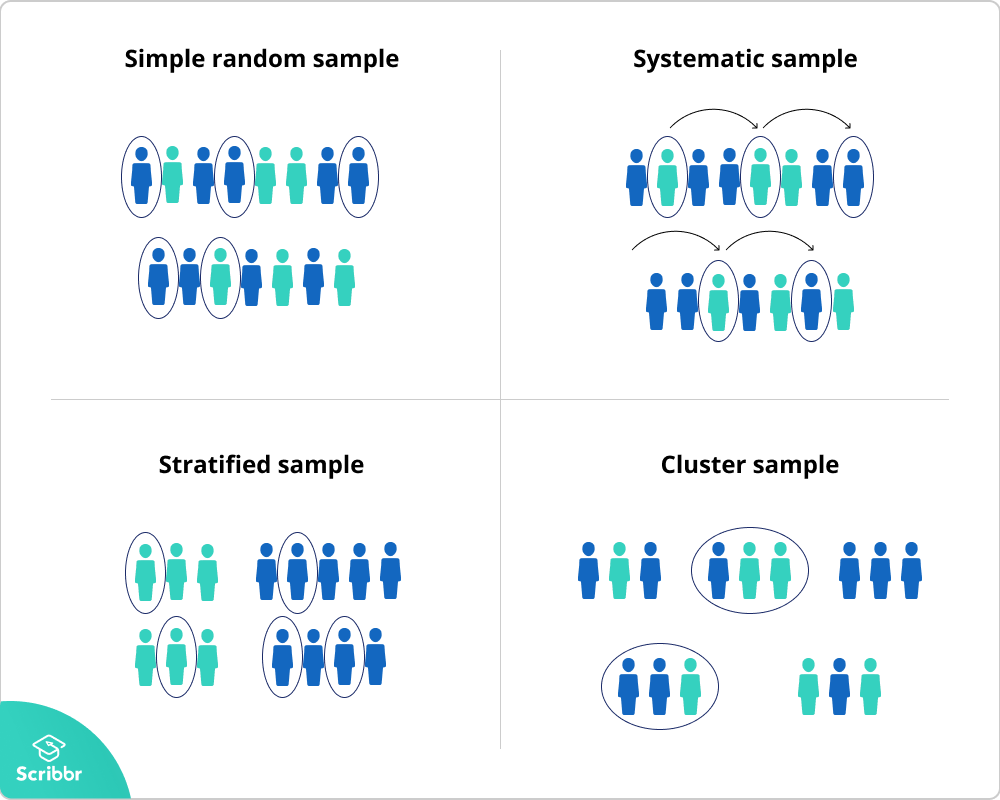
In a simple random sample, every unit has an equal and non-zero probability of selection. Common examples would be bingo machines or lotteries. The selection machine gives each ball the same chance of appearing.
Systematic sampling assigns every unit a unique number. A systematic sample starts at a random point, then picks units at regular intervals.
Suppose there were 1,000 tents at a festival. The researcher wants to survey 100 tents. They pick a number between one and 10: such as seven. The researcher then chooses every tenth tent: 7th, 17th, 27th, 37th tents, and so on. The sample is then of 100 tents.
There are several advantages to systematic sampling:
- Easier to conduct: Systematic samples are simpler to construct than simple random samples.
- Eliminating clusters: By chance, simple random samples can select units which are close. This does not happen in systematic sampling.
There are disadvantages too:
- A determined population size: we need to know or approximate the population size.
- Need for natural randomness: there should no hidden pattern in the numbered population. For example, an employee database could group people by their teams. A systematic sample runs the risk of including too many or too few senior employees.
With a set sampling fraction, researchers do not need to know how big the population is. This is why systematic sampling is common for web intercept surveys. The sampling choice is to invite a fixed fraction of website users to answer questions.
Another application of systematic sampling is forest inventory.
